典名科技本文介绍阿里云服务器GPU云服务器机器学习,如何在GPU实例上安装和使用cGPU服务,FastGPU构建一键训练任务,希望对您有所帮助。
使用cGPU服务隔离GPU资源
| 环境变量名称 | 取值类型 | 说明 | 示例 |
|---|---|---|---|
| CGPU_DISABLE | Boolean | 是否启用cGPU服务,取值范围:
| 无 |
| ALIYUN_COM_GPU_MEM_DEV | Integer | 设置GPU实例上每张显卡的总显存大小,和实例规格有关。 说明 显存大小按GiB取整数。 | 一台GPU实例规格为ecs.gn6i-c4g1.xlarge,配备1张NVIDIA ® Tesla ® T4显卡。在GPU实例上执行nvidia-smi查看总显存大小为15109 MiB,取整数为15 GiB。 |
| ALIYUN_COM_GPU_MEM_CONTAINER | Integer | 设置容器内可见的显存大小,和ALIYUN_COM_GPU_MEM_DEV结合使用。如果不指定本参数或指定为0,则不使用cGPU服务,使用默认的NVIDIA容器服务。 | 在一张总显存大小为15 GiB的显卡上,设置环境变量ALIYUN_COM_GPU_MEM_DEV=15和ALIYUN_COM_GPU_MEM_CONTAINER=1,效果是为容器分配1 GiB的显存。 |
| ALIYUN_COM_GPU_VISIBLE_DEVICES | Integer或uuid | 指定容器内可见的GPU显卡。 | 在一台有4张显卡的GPU实例上,执行nvidia-smi -L查看GPU显卡设备号和UUID。返回示例如下所示:然后,设置以下环境变量:
|
| ALIYUN_COM_GPU_SCHD_WEIGHT | Integer | 设置容器的算力权重,取值范围:1~min(max_inst, 16)。 | 无 |
以ecs.gn6i-c4g1.xlarge为例演示2个容器共用1张显卡。
nvidia-smi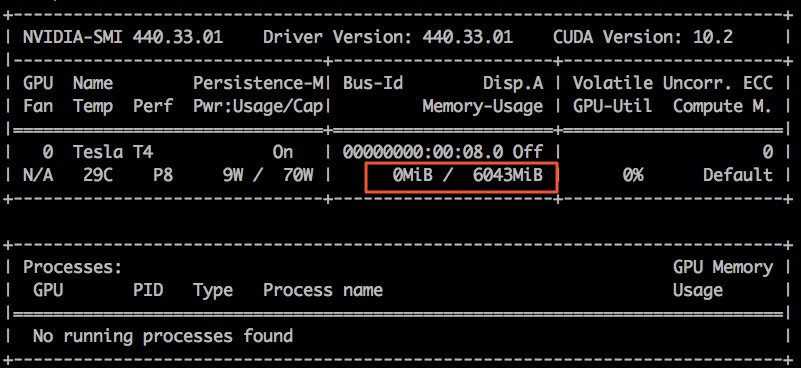
cGPU服务运行时会在/proc/cgpu_km下生成并自动管理多个procfs节点,您可以通过procfs节点查看和配置cGPU服务相关的信息。下面介绍各procfs节点的用途。
| 命令 | 效果 |
|---|---|
| echo 2 > /proc/cgpu_km/0/policy | 将调度策略切换为权重抢占调度。 |
| cat /proc/cgpu_km/0/free_weight | 查看显卡上可用的权重。 如果free_weight=0,新创建容器的权重值为0,该容器不能获取GPU算力,不能用于运行需要GPU算力的应用。 |
| cat /proc/cgpu_km/0/$dockerid/weight | 查看指定容器的权重。 |
| echo 4 > /proc/cgpu_km/0/$dockerid/weight | 修改容器获取GPU算力的权重。 |
1/max_inst。如下图所示。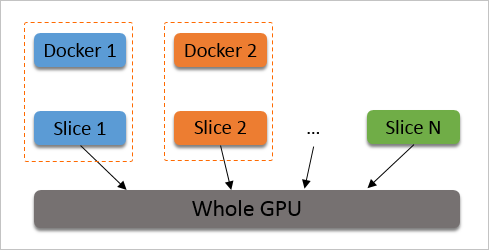
在创建容器时,为容器分配时间片。cGPU服务会从Slice 1开始调度,但如果没有使用某个容器,或者容器内没有进程打开GPU设备,则跳过调度,切换到下一个时间片。
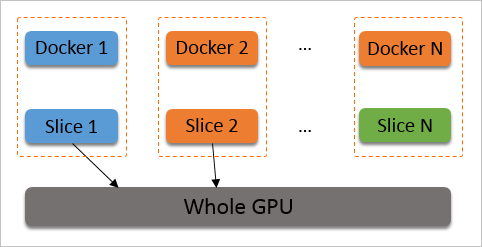
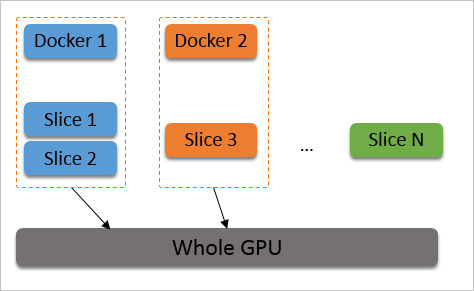
如果在创建容器时设置ALIYUN_COM_GPU_SCHD_WEIGHT大于1,则自动使用权重抢占调度。cGPU服务按照容器数量(max_inst)将物理GPU算力划分成max_inst份,但如果ALIYUN_COM_GPU_SCHD_WEIGHT大于1,cGPU服务会将数个时间片组合成一个更大的时间片分配给容器。
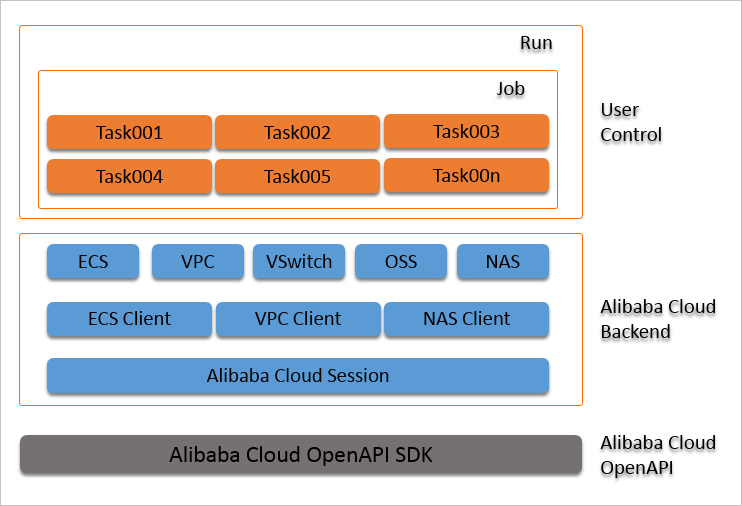
本步骤以在Cloud Shell中运行BERT finetune任务为例,展示如何使用FastGPU。demo中自动创建的实例规格为ecs.gn6v-c10g1.20xlarge(8卡V100机型),任务部署时间约2.5分钟,训练时长约11.5分钟,总共耗时约14分钟,训练精度达到0.88以上。
python train_news_classifier.py

ecluster ls
ecluster tmux task0.perseus-bert
export ALIYUN_ACCESS_KEY_ID=L**** # Your actual aliyun access key id
export ALIYUN_ACCESS_KEY_SECRET=v**** # Your actual aliyun access key secret
export ALIYUN_DEFAULT_REGION=cn-hangzhou # The actual region the resource you want to use
export ALIYUN_DEFAULT_ZONE=cn-hangzhou-i # The actual zone of the region you want to useimport nclusterjob = ncluster.make_job(name=args.name,
run_name=f"{args.name}-{args.machines}",
num_tasks=args.machines,
image_name=IMAGE_NAME,
instance_type=INSTANCE_TYPE)| 参数名称 | 参数说明 | 参数示例 |
|---|---|---|
| name | job的名称。 | 'perseus-bert' |
| run_name | 运行时的环境名,一般设置为job名+实例数量。 | f"perseus-bert-1" |
| num_tasks | 需要创建实例的个数。 | 1 表示创建1台实例,名称为task0.perseus-bert,对应perseus-bert.tasks[0]。 |
| image_name | 实例使用的镜像,支持公共镜像和自定义镜像。 | 'ubuntu_18_04_64_20G_alibase_20190624.vhd' |
| instance_type | 需要创建实例的实例规格。 | 'ecs.gn6v-c10g1.20xlarge' |
# 为job中所有实例打开perseus-bert文件夹
job.run('cd perseus-bert')
# 将当前目录中的perseus-bert文件夹上传到job中所有实例的/root目录下
job.upload('perseus-bert')# 为task0对应实例打开perseus-bert文件夹
job.tasks[0].run('cd perseus-bert')
# 将当前目录中的perseus-bert文件夹上传到task0对应实例的/root目录下
job.tasks[0].upload('perseus-bert')| 命令 | 命令说明 | 命令示例 |
|---|---|---|
| export | 获取阿里云账号的信息,在本地机器使用FastGPU时需要获取AccessKey、默认地域、默认可用区等信息。 |
|
| ecluster [help,-h,--help] | 查看所有ecluster命令。 | ecluster --help |
| ecluster {command} --help | 查看指定的ecluser命令。 | ecluster ls --help |
| ecluster create --config create.cfg | 基于配置文件创建实例。create.cfg文件定义实例的配置环境,运行命令前您需要先创建create.cfg文件,具体内容请参见表格下方的示例。 | ecluster create --config create.cfg |
| ecluster create --name {instance_name} --machines {instance_num} ... | 基于参数创建实例。 | ecluster create --name task0.ncluster-v100 --machines 1 |
| ecluster ls | 列出已自动创建的实例。包括以下信息:
| ecluster ls |
| ecluster ssh {instance_name} | 登录指定的实例。 | ecluster ssh task0.ncluster-v100 |
| ecluster tmux {instance_name} | 连接到运行中的任务,如果没有tmux会话,则使用ssh连接。 | ecluster tmux task0.ncluster-v100 |
| ecluster stop {instance_name} | 停止指定的实例。 |
|
| ecluster start {instance_name} | 启动指定的实例。 |
|
| ecluster kill {instance_name} | 释放指定的实例。 |
|
| ecluster mount {instance_name} | 为指定的实例挂载NAS文件系统到/ncluster目录。 | ecluster mount task0.ncluster-v100 |
| ecluster scp {source} {destination} | 安全拷贝文件或目录。 | ecluster scp /local/path/to/upload task0.ncluster-v100:/remote/path/to/save |
| ecluster addip {instance_name} | 将指定任务中实例的固定公网IP添加到安全组。 | ecluster addip task0.ncluster-v100 |
| ecluster rename {old_name} {new_name} | 重命名指定实例。 | ecluster rename task0.ncluster-v100 task1.ncluster-v100 |
; config.ini
[ncluster]
; The job name for current creation job.
name=ncluster-v100
; The number of machine you want to create
machines=1
; The system disk size for instances in GB
system_disk_size=300
; The data disk size for instances in GB
data_disk_size=0
; The system image name you want to installed in the instances.
image_name=ubuntu_18_04_64_20G_alibase_20190624.vhd
; The instance type you want to create at Alibaba Cloud.
instance_type=ecs.gn6v-c10g1.20xlarge
; The spot instance option; If you want to buy spot instance, please set it to True.
spot=False
; If only used to create instances, it can set to True.
confirm_cost=False
; Confirm the next operation will cost money, if set to True will default confirmed.
skip_setup=True
; Nas create/mount options; Set True will disable nas mount for current job.
disable_nas=True
; The zone id info. The option provided to use resource in the zone.
zone_id=cn-hangzhou-i
; Specify the vpc name
vpc_name=ncluster-vpc
[cmd]
install_script=pwd


